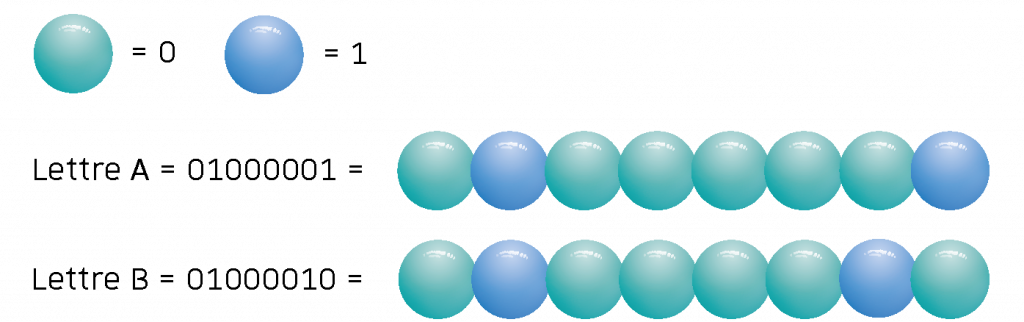
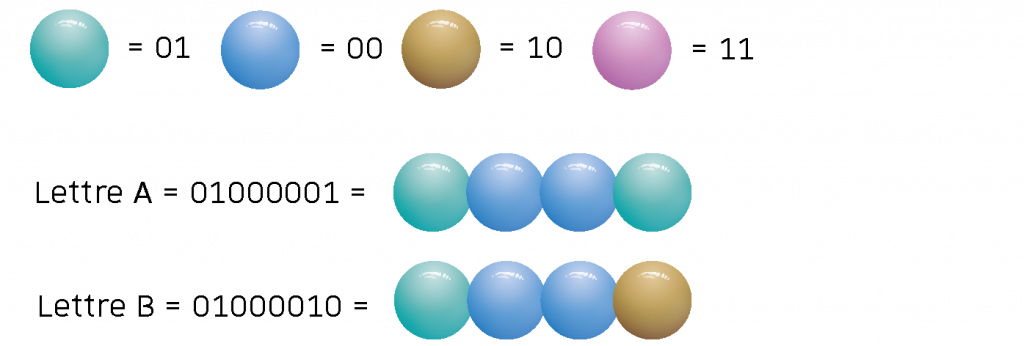Qu’elles soient stockées dans le plastique ou l’ADN, comment rendre accessible rapidement ces données ?
En effet, pour extraire les informations stockées dans l’ADN, un équipement de séquençage est nécessaire et l’opération est lente et coûteuse. La lecture des polymères est également loin d’être instantanée et nécessite l’utilisation d’un spectromètre de masse. En 2017, Le laboratoire de Jean-François Lutz (en collaboration avec l’Institut de Chimie Radicalaire de Marseille) a établi un record mondial en termes de quantité d’information pouvant être séquencée par spectrométrie de masse5. Ces résultats, publiés dans la revue Nature Communications, ont conférés aux chercheurs français une solide réputation internationale, un atout français de poids dans cet axe de recherche stratégique.
Aujourd’hui, ce type de stockage semble être indiqué pour l’archivage de données dites « froides » (c’est-à-dire des données auxquelles l’accès est peu fréquent). Demain, avec l’amélioration des équipements permettant la synthèse et la lecture de ces polymères, ce type de support de stockage pourraient bien révolutionner le secteur.